Query Lifecycle & Performance
Understanding how ZQL manages query lifecycles and performance is crucial for building efficient applications. This page covers query states, background synchronization, client capacity management, and performance optimization strategies.
Query Lifecycle
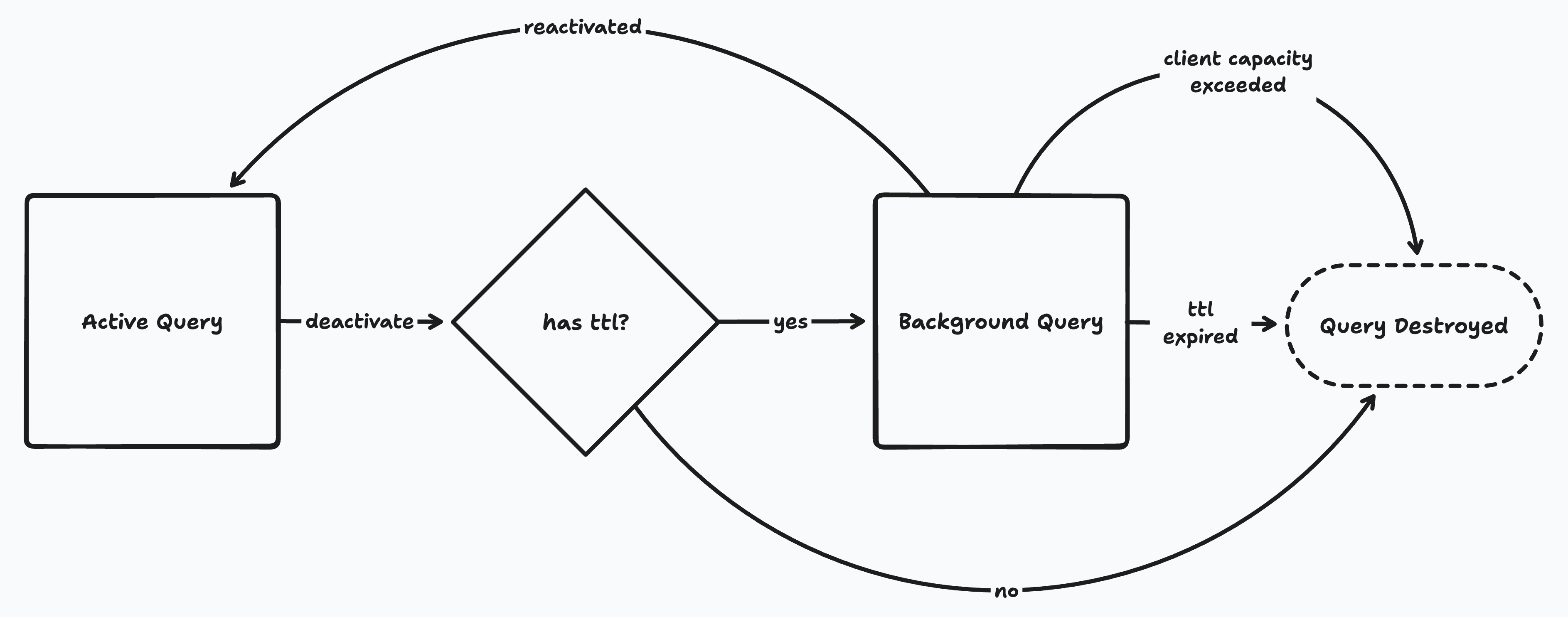
Queries can be either active or backgrounded. An active query is one that is currently being used by the application. Backgrounded queries are not currently in use, but continue syncing in case they are needed again soon.
Creating Active Queries
Active queries are created one of three ways:
- View Materialization: The app calls
q.materialize()to get aView. - Framework Bindings: The app uses a platform binding like React's
useQuery(q). - Preloading: The app calls
preload()to sync larger queries without a view.
// 1. Direct materialization
const view = z.query.issue.materialize();
// 2. Framework binding (React)
const [issues] = useQuery(z.query.issue.orderBy('created', 'desc'));
// 3. Preloading
z.query.issue.limit(1000).preload();
Deactivating Queries
Active queries sync until they are deactivated. The way this happens depends on how the query was created:
- For
materialize()queries: The UI callsdestroy()on the view. - For
useQuery(): The UI unmounts the component (which callsdestroy()under the covers). - For
preload(): The UI callscleanup()on the return value ofpreload().
// Manual cleanup for materialized views
const view = z.query.issue.materialize();
// ... use the view
view.destroy(); // Cleanup
// Automatic cleanup for React hooks
function MyComponent() {
const [issues] = useQuery(z.query.issue); // Active while mounted
return <div>{/* render issues */}</div>;
} // Automatically deactivated when unmounted
// Manual cleanup for preloaded queries
const cleanup = z.query.issue.limit(1000).preload();
// ... later
cleanup(); // Stop syncing
Background Queries
By default a deactivated query stops syncing immediately. But it's often useful to keep queries syncing beyond deactivation in case the UI needs the same or a similar query in the near future.
Time-To-Live (TTL)
This is accomplished with the ttl parameter:
const [user] = useQuery(z.query.user.where('id', userId), {ttl: '1d'});
The ttl parameter specifies how long the app developer wishes the query to run in the background. The following formats are allowed (where %d is a positive integer):
| Format | Meaning |
|---|---|
none | No backgrounding. Query will immediately stop when deactivated. This is the default. |
%ds | Number of seconds. |
%dm | Number of minutes. |
%dh | Number of hours. |
%dd | Number of days. |
%dy | Number of years. |
forever | Query will never be stopped. |
Background Query Benefits
If the UI re-requests a background query, it becomes an active query again. Since the query was syncing in the background, the very first synchronous result that the UI receives after reactivation will be up-to-date with the server (i.e., it will have resultType of complete).
// Common pattern: preload with forever TTL, then use shorter TTLs in UI
z.query.issue
.related('creator')
.related('assignee')
.related('labels')
.orderBy('created', 'desc')
.limit(1000)
.preload({ttl: 'forever'}); // Keep syncing forever
// Later in UI components
const [issues] = useQuery(
z.query.issue.where('assignee', currentUser),
{ttl: '1d'}, // Background for a day after unmount
);
Client Capacity Management
Zero has a default soft limit of 20,000 rows on the client-side, or about 20MB of data assuming 1KB rows.
This limit can be increased with the --target-client-row-count flag, but we do not recommend setting it higher than 100,000.
Why Store So Little Data Client-Side?
Capacity Management Rules
Here is how this limit is managed:
- Active queries are never destroyed, even if the limit is exceeded. Developers are expected to keep active queries well under the limit.
- The
ttlvalue counts from the moment a query deactivates. Backgrounded queries are destroyed immediately when thettlis reached, even if the limit hasn't been reached. - If the client exceeds its limit, Zero will destroy backgrounded queries, least-recently-used first, until the store is under the limit again.
// Good: Keep active queries small and focused
const [recentIssues] = useQuery(
z.query.issue.orderBy('created', 'desc').limit(50),
);
// Be careful: Large active queries can exceed capacity
const [allIssues] = useQuery(z.query.issue); // Could be 100k+ rows
// Good: Use preloading with appropriate limits for large datasets
z.query.issue.limit(5000).preload({ttl: '1h'});
Data Lifetime and Reuse
Zero reuses data synced from prior queries to answer new queries when possible. This is what enables instant UI transitions.
What Controls Data Lifetime?
The data on the client is simply the union of rows returned from queries which are currently syncing. Once a row is no longer returned by any syncing query, it is removed from the client. Thus, there is never any stale data in Zero.
// These queries share data - only one copy of each issue is stored
const activeQuery1 = z.query.issue.where('status', 'open');
const activeQuery2 = z.query.issue.where('priority', 'high');
// Issues that are both open AND high priority exist in both result sets
// but are stored only once on the client
Caches vs Replicas
Performance Optimization
Thinking in Queries
Although IVM (Incremental View Maintenance) is a very efficient way to keep queries up to date relative to re-running them, it isn't free. You still need to think about how many queries you are creating, how long they are kept alive, and how expensive they are.
This is why Zero defaults to not backgrounding queries and doesn't try to aggressively fill its client datastore to capacity. You should put some thought into what queries you want to run in the background, and for how long.
Performance Monitoring
Zero currently provides a few basic tools to understand the cost of your queries:
- Client slow query warnings: The client logs a warning for slow query materializations. Look for
Slow query materializationin your logs. The default threshold is5s(including network) but this is configurable with theslowMaterializeThresholdparameter. - Client debug logs: The client logs the materialization time of all queries at the
debuglevel. Look forMaterialized queryin your logs. - Server slow query warnings: The server logs a warning for slow query materializations. Look for
Slow query materializationin your logs. The default threshold is5sbut this is configurable with thelog-slow-materialize-thresholdconfiguration parameter.
// Configure slow query thresholds
const z = new Zero({
slowMaterializeThreshold: 3000, // 3 seconds (client)
// ... other options
});
Optimization Strategies
1. Strategic Preloading
// Preload common data patterns to maximize instant results
z.query.issue
.related('creator')
.related('assignee')
.related('labels')
.orderBy('created', 'desc')
.limit(1000)
.preload({ttl: 'forever'});
// Preload different sort orders for instant UI transitions
z.query.issue.orderBy('priority', 'desc').limit(500).preload({ttl: '1d'});
z.query.issue.orderBy('updated', 'desc').limit(500).preload({ttl: '1d'});
2. Appropriate TTL Management
// Forever TTL for core data
z.query.user.where('id', currentUserId).preload({ttl: 'forever'});
// Medium TTL for frequently accessed data
const [issues] = useQuery(z.query.issue.where('assignee', currentUserId), {
ttl: '1d',
});
// Short TTL for specific views
const [issue] = useQuery(z.query.issue.where('id', issueId), {ttl: '1h'});
// No TTL for one-off queries
const [searchResults] = useQuery(
z.query.issue.where('title', 'LIKE', searchTerm),
);
3. Query Composition
// Build queries incrementally to reuse logic
function useIssueQuery(filters: IssueFilters, options?: {ttl?: string}) {
let query = z.query.issue;
if (filters.assignee) {
query = query.where('assignee', filters.assignee);
}
if (filters.status) {
query = query.where('status', 'IN', filters.status);
}
return useQuery(query.orderBy('created', 'desc').limit(100), options);
}
Best Practices
- Keep active queries focused: Limit active queries to what's actually displayed
- Use preloading strategically: Preload common patterns, not everything
- Set appropriate TTLs: Longer for frequently re-accessed data, shorter for specific views
- Monitor performance: Watch for slow query warnings in your logs
- Design for 99% instant: Accept that some queries will need server round trips
- Compose queries thoughtfully: Build reusable query patterns
Next Steps
Now that you understand query lifecycle and performance, explore these related topics:
- Data Synchronization - Learn about completeness and consistency
- Advanced Query Patterns - Master preloading and optimization techniques
- Relationships - Understand relationship performance implications
- ZQL Fundamentals - Review the basics if needed